16 PAGING
16 分页
We have covered a lot of interesting features while creating our Web API project, but there are still things to do.
在创建 Web API 项目时,我们已经介绍了许多有趣的功能,但仍有一些事情要做。
So, in this chapter, we’re going to learn how to implement paging in ASP.NET Core Web API. It is one of the most important concepts in building RESTful APIs.
因此,在本章中,我们将学习如何在 ASP.NET Core Web API 中实现分页。它是构建 RESTful API 中最重要的概念之一。
If we inspect the GetEmployeesForCompany action in the EmployeesController, we can see that we return all the employees for the single company.
如果我们检查 EmployeesController 中的 GetEmployeesForCompany作,我们可以看到我们返回了单个公司的所有员工。
But we don’t want to return a collection of all resources when querying our API. That can cause performance issues and it’s in no way optimized for public or private APIs. It can cause massive slowdowns and even application crashes in severe cases.
但是,在查询 API 时,我们不想返回所有资源的集合。这可能会导致性能问题,并且它绝不会针对公有或私有 API 进行优化。它可能会导致大规模减速,严重时甚至会导致应用程序崩溃。
Of course, we should learn a little more about Paging before we dive into code implementation.
当然,在深入研究代码实现之前,我们应该更多地了解 Paging。
16.1 What is Paging?
16.1 什么是分页?
Paging refers to getting partial results from an API. Imagine having millions of results in the database and having your application try to return all of them at once.
分页是指从 API 获取部分结果。想象一下,数据库中有数百万个结果,并让您的应用程序尝试一次返回所有结果。
Not only would that be an extremely ineffective way of returning the results, but it could also possibly have devastating effects on the application itself or the hardware it runs on. Moreover, every client has limited memory resources and it needs to restrict the number of shown results.
这不仅是一种极其无效的返回结果的方式,而且还可能对应用程序本身或运行它的硬件产生毁灭性的影响。此外,每个客户端的内存资源都是有限的,它需要限制显示的结果的数量。
Thus, we need a way to return a set number of results to the client in order to avoid these consequences. Let’s see how we can do that.
因此,我们需要一种方法将一定数量的结果返回给客户端,以避免这些后果。让我们看看如何做到这一点。
16.2 Paging Implementation
16.2 分页实现
Mind you, we don’t want to change the base repository logic or implement any business logic in the controller.
请注意,我们不想更改基本存储库逻辑或在控制器中实现任何业务逻辑。
What we want to achieve is something like this: https://localhost:5001/api/companies/companyId/employees?pa geNumber=2&pageSize=2. This should return the second set of two employees we have in our database.
我们想要实现的是这样的:https://localhost:5001/api/companies/companyId/employees?pageNumber=2&pageSize=2。这应该返回我们数据库中的第二组两个员工。
We also want to constrain our API not to return all the employees even if someone calls https://localhost:5001/api/companies/companyId/employees.
我们还希望约束我们的 API 不会返回所有员工,即使有人调用 https://localhost:5001/api/companies/companyId/employees。
Let's start with the controller modification by modifying the GetEmployeesForCompany action:
让我们通过修改 GetEmployeesForCompany作来从控制器修改开始:
[HttpGet]
// public async Task<IActionResult> GetEmployeesForCompany(Guid companyId)
public async Task<IActionResult> GetEmployeesForCompany(Guid companyId, [FromQuery] EmployeeParameters employeeParameters)
{
var employees = await _service.EmployeeService.GetEmployeesAsync(companyId, trackChanges: false);
return Ok(employees);
}A few things to take note of here:
这里需要注意以下几点:
• We’re using [FromQuery] to point out that we’ll be using query parameters to define which page and how many employees we are requesting.
我们使用 [FromQuery] 来指出,我们将使用查询参数来定义我们请求的页面和员工数量。
• The EmployeeParameters class is the container for the actual parameters for the Employee entity.
EmployeeParameters 类是 Employee 实体的实际参数的容器。
We also need to actually create the EmployeeParameters class. So, let’s first create a RequestFeatures folder in the Shared project and then inside, create the required classes.
我们还需要实际创建 EmployeeParameters 类。因此,让我们首先在 Shared 项目中创建一个 RequestFeatures 文件夹,然后在其中创建所需的类。
First the RequestParameters class:
首先是 RequestParameters 类:
namespace Shared.RequestFeatures
{
public abstract class RequestParameters
{
const int maxPageSize = 50;
public int PageNumber { get; set; } = 1;
private int _pageSize = 10;
public int PageSize
{
get { return _pageSize; }
set { _pageSize = (value > maxPageSize) ? maxPageSize : value; }
}
}
}And then the EmployeeParameters class:
然后是 EmployeeParameters 类:
namespace Shared.RequestFeatures
{
public class EmployeeParameters : RequestParameters { }
}We create an abstract class to hold the common properties for all the entities in our project, and a single EmployeeParameters class that will hold the specific parameters. It is empty now, but soon it won’t be.
我们创建一个抽象类来保存项目中所有实体的公共属性,并创建一个 EmployeeParameters 类来保存特定参数。它现在是空的,但很快就会空了。
In the abstract class, we are using the maxPageSize constant to restrict our API to a maximum of 50 rows per page. We have two public properties – PageNumber and PageSize. If not set by the caller, PageNumber will be set to 1, and PageSize to 10.
在抽象类中,我们使用 maxPageSize 常量将 API 限制为每页最多 50 行。我们有两个公共属性 – PageNumber 和 PageSize。如果调用方未设置,则 PageNumber 将设置为 1,PageSize 将设置为 10。
Now we can return to the controller and import a using directive for the EmployeeParameters class:
现在我们可以返回到控制器并导入 EmployeeParameters 类的 using 指令:
using Shared.RequestFeatures;After that change, let’s implement the most important part — the repository logic. We need to modify the GetEmployeesAsync method in the IEmployeeRepository interface and the EmployeeRepository class.
更改之后,让我们实现最重要的部分 — 存储库逻辑。我们需要修改 IEmployeeRepository 接口中的 GetEmployeesAsync 方法和 EmployeeRepository 类。
So, first the interface modification:
所以,首先进行接口修改:
using Entities.Models;
using Shared.RequestFeatures;
namespace Contracts;
public interface IEmployeeRepository
{
// Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, bool trackChanges);
Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);
Task<Employee> GetEmployeeAsync(Guid companyId, Guid id, bool trackChanges);
void CreateEmployeeForCompany(Guid companyId, Employee employee);
void DeleteEmployee(Employee employee);
}As Visual Studio suggests, we have to add the reference to the Shared project.
正如 Visual Studio 所建议的,我们必须添加对 Shared 项目的引用。
After that, let’s modify the repository logic:
之后,让我们修改仓库逻辑:
//public async Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, bool trackChanges) =>
// await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges)
// .OrderBy(e => e.Name)
// .ToListAsync();
public async Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges) =>
await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges)
.OrderBy(e => e.Name)
.Skip((employeeParameters.PageNumber - 1) * employeeParameters.PageSize)
.Take(employeeParameters.PageSize)
.ToListAsync();Okay, the easiest way to explain this is by example.
好的,解释这一点的最简单方法是举例说明。
Say we need to get the results for the third page of our website, counting 20 as the number of results we want. That would mean we want to skip the first ((3 – 1) 20) = 40 results, then take the next 20 and return them to the caller.
假设我们需要获取网站第三页的结果,将 20 算作我们想要的结果数。这意味着我们要跳过第一个 ((3 – 1) 20) = 40 个结果,然后获取接下来的 20 个结果并将它们返回给调用者。
Does that make sense?
这有意义吗?
Since we call this repository method in our service layer, we have to modify it as well.
由于我们在服务层中调用此存储库方法,因此我们也必须对其进行修改。
So, let’s start with the IEmployeeService modification:
那么,让我们从 IEmployeeService 修改开始:
using Entities.Models;
using Shared.DataTransferObjects;
using Shared.RequestFeatures;
namespace Service.Contracts;
public interface IEmployeeService
{
// Task<IEnumerable<EmployeeDto>> GetEmployeesAsync(Guid companyId, bool trackChanges);
Task<IEnumerable<EmployeeDto>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);
// ...
}In this interface, we only have to modify the GetEmployeesAsync method by adding a new parameter.
在此接口中,我们只需通过添加新参数来修改 GetEmployeesAsync 方法。
After that, let’s modify the EmployeeService class:
之后,我们来修改 EmployeeService 类:
//public async Task<IEnumerable<EmployeeDto>> GetEmployeesAsync(Guid companyId, bool trackChanges)
//{
// await CheckIfCompanyExists(companyId, trackChanges);
// var employeesFromDb = await _repository.Employee.GetEmployeesAsync(companyId, trackChanges);
// var employeesDto = _mapper.Map<IEnumerable<EmployeeDto>>(employeesFromDb);
// return employeesDto;
//}
public async Task<IEnumerable<EmployeeDto>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges)
{
await CheckIfCompanyExists(companyId, trackChanges);
var employeesFromDb = await _repository.Employee.GetEmployeesAsync(companyId, employeeParameters, trackChanges);
var employeesDto = _mapper.Map<IEnumerable<EmployeeDto>>(employeesFromDb);
return employeesDto;
}Nothing too complicated here. We just accept an additional parameter and pass it to the repository method.
这里没什么太复杂的。我们只接受一个额外的参数并将其传递给 repository 方法。
Finally, we have to modify the GetEmployeesForCompany action and fix that error by adding another argument to the GetEmployeesAsync method call:
最后,我们必须修改 GetEmployeesForCompany作,并通过向 GetEmployeesAsync 方法调用添加另一个参数来修复该错误:
[HttpGet]
public async Task<IActionResult> GetEmployeesForCompany(Guid companyId, [FromQuery] EmployeeParameters employeeParameters)
{
var employees = await _service.EmployeeService.GetEmployeesAsync(companyId, employeeParameters, trackChanges: false);
return Ok(employees);
}16.3 Concrete Query
16.3 具体查询
Before we continue, we should create additional employees for the company with the id: C9D4C053-49B6-410C-BC78-2D54A9991870. We are doing this because we have only a small number of employees per company and we need more of them for our example. You can use a predefined request in Part16 in Postman, and just change the request body with the following objects:
在我们继续之前,我们应该为 ID 为 C9D4C053-49B6-410C-BC78-2D54A9991870 的公司创建额外的员工。我们这样做是因为每家公司只有少量员工,我们需要更多的员工来证明我们的示例。您可以在 Postman 的 Part16 中使用预定义的请求,只需使用以下对象更改请求正文:
| {"name": "Mihael Worth","age": 30,"position": "Marketing expert"} | {"name": "John Spike","age": 32,"position": "Marketing expert II"} | {"name": "Nina Hawk","age": 26,"position": "Marketing expert II"} |
| {"name": "Mihael Fins","age": 30,"position": "Marketing expert" } | {"name": "Martha Grown","age": 35, "position": "Marketing expert II"} | {"name": "Kirk Metha","age": 30,"position": "Marketing expert" } |
Now we should have eight employees for this company, and we can try a request like this:
现在,这家公司应该有 8 名员工,我们可以尝试如下请求:
So, we request page two with two employees:
因此,我们请求第 2 页有两名员工:
https://localhost:5001/api/companies/C9D4C053-49B6-410C-BC78- 2D54A9991870/employees?pageNumber=2&pageSize=2
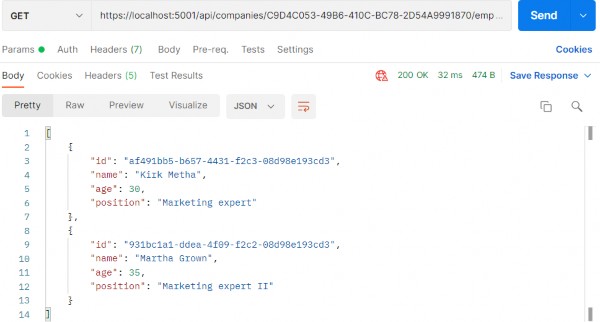
If that’s what you got, you’re on the right track. We can check our result in the database:
如果这就是你得到的,那你就走在正确的轨道上。我们可以在数据库中检查我们的结果:

And we can see that we have the correct data returned.
我们可以看到我们返回了正确的数据。
Now, what can we do to improve this solution?
现在,我们能做些什么来改进这个解决方案呢?
16.4 Improving the Solution
16.4 改进解决方案
Since we’re returning just a subset of results to the caller, we might as well have a PagedList instead of List.
由于我们只向调用者返回结果的子集,因此我们也可以使用 PagedList 而不是 List。
PagedList will inherit from the List class and will add some more to it. We can also move the skip/take logic to the PagedList since it makes more sense.
PagedList 将从 List 类继承,并向其添加更多内容。我们还可以将 skip/take 逻辑移动到 PagedList,因为它更有意义。
So, let’s first create a new MetaData class in the Shared/RequestFeatures folder:
因此,让我们首先在 Shared/RequestFeatures 文件夹中创建一个新的 MetaData 类:
namespace Shared.RequestFeatures
{
public class MetaData {
public int CurrentPage { get; set; }
public int TotalPages { get; set; }
public int PageSize { get; set; }
public int TotalCount { get; set; }
public bool HasPrevious => CurrentPage > 1;
public bool HasNext => CurrentPage < TotalPages; }
}Then, we are going to implement the PagedList class in the same folder:
然后,我们将在同一文件夹中实现 PagedList 类:
namespace Shared.RequestFeatures
{
public class PagedList<T> : List<T>
{
public MetaData MetaData { get; set; }
public PagedList(List<T> items, int count, int pageNumber, int pageSize)
{
MetaData = new MetaData
{
TotalCount = count,
PageSize = pageSize,
CurrentPage = pageNumber,
TotalPages = (int)Math.Ceiling(count / (double)pageSize)
};
AddRange(items);
}
public static PagedList<T> ToPagedList(IEnumerable<T> source, int pageNumber, int pageSize)
{
var count = source.Count();
var items = source
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToList();
return new PagedList<T>(items, count, pageNumber, pageSize);
}
}
}As you can see, we’ve transferred the skip/take logic to the static method inside of the PagedList class. And in the MetaData class, we’ve added a few more properties that will come in handy as metadata for our response.
如你所见,我们已将 skip/take 逻辑转移到 PagedList 类内的静态方法。在 MetaData 类中,我们添加了更多属性,这些属性将作为响应的元数据派上用场。
HasPrevious is true if the CurrentPage is larger than 1, and HasNext is calculated if the CurrentPage is smaller than the number of total pages. TotalPages is calculated by dividing the number of items by the page size and then rounding it to the larger number since a page needs to exist even if there is only one item on it.
如果 CurrentPage 大于 1,则 HasPrevious 为 true,如果 CurrentPage 小于总页数,则计算 HasNext。TotalPages 的计算方法是将项目数除以页面大小,然后将其四舍五入为更大的数字,因为即使页面上只有一个项目,页面也需要存在。
Now that we’ve cleared that up, let’s change our EmployeeRepository and EmployeesController accordingly.
现在我们已经清除了这个问题,让我们相应地更改我们的 EmployeeRepository 和 EmployeesController。
Let’s start with the interface modification:
让我们从接口修改开始:
// Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);
Task<PagedList<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);Then, let’s change the repository class:
然后,让我们更改 repository 类:
// public async Task<IEnumerable<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges) =>
//await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges)
//.OrderBy(e => e.Name)
//.Skip((employeeParameters.PageNumber - 1) * employeeParameters.PageSize)
//.Take(employeeParameters.PageSize)
//.ToListAsync();
public async Task<PagedList<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges) {
var employees = await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges).OrderBy(e => e.Name).ToListAsync();
return PagedList<Employee>.ToPagedList(employees, employeeParameters.PageNumber, employeeParameters.PageSize);
}After that, we are going to modify the IEmplyeeService interface:
之后,我们将修改 IEmplyeeService 接口:
// Task<IEnumerable<EmployeeDto>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);
Task<(IEnumerable<EmployeeDto> employees, MetaData metaData)> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges);Now our method returns a Tuple containing two fields – employees and metadata.
现在,我们的方法返回一个包含两个字段的 Tuple – employees 和 metadata。
So, let’s implement that in the EmployeeService class:
因此,让我们在 EmployeeService 类中实现它:
public async Task<(IEnumerable<EmployeeDto> employees, MetaData metaData)> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges)
{
await CheckIfCompanyExists(companyId, trackChanges);
var employeesWithMetaData = await _repository.Employee.GetEmployeesAsync(companyId, employeeParameters, trackChanges);
var employeesDto = _mapper.Map<IEnumerable<EmployeeDto>>(employeesWithMetaData);
return (employees: employeesDto, metaData: employeesWithMetaData.MetaData);
}We change the method signature and the name of the employeesFromDb variable to employeesWithMetaData since this name is now more suitable. After the mapping action, we construct a Tuple and return it to the caller.
我们将方法签名和 employeesFromDb 变量的名称更改为 employeesWithMetaData,因为此名称现在更合适。在 mapping作之后,我们构造一个 Tuple 并将其返回给调用者。
Finally, let’s modify the controller:
最后,我们来修改控制器:
[HttpGet]
public async Task<IActionResult> GetEmployeesForCompany(Guid companyId, [FromQuery] EmployeeParameters employeeParameters)
{
var pagedResult = await _service.EmployeeService.GetEmployeesAsync(companyId, employeeParameters, trackChanges: false);
Response.Headers.Add("X-Pagination", JsonSerializer.Serialize(pagedResult.metaData));
return Ok(pagedResult.employees);
} The new thing in this action is that we modify the response header and add our metadata as the X-Pagination header. For this, we need the System.Text.Json namespace.
这个动作的新内容是我们修改响应标头并将我们的元数据添加为 X-Pagination 标头。为此,我们需要 System.Text.Json 命名空间。
Now, if we send the same request we did earlier, we are going to get the same result:
现在,如果我们发送之前所做的相同请求,我们将得到相同的结果:
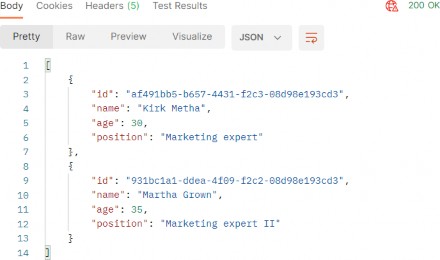
But now we have some additional useful information in the X-Pagination response header:
但是现在我们在 X-Pagination 响应标头中有一些额外的有用信息:
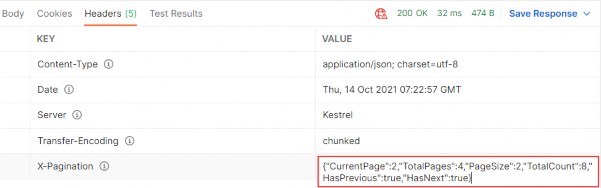
As you can see, all of our metadata is here. We can use this information when building any kind of frontend pagination to our benefit. You can play around with different requests to see how it works in other scenarios.
如您所见,我们所有的元数据都在这里。我们可以在构建任何类型的前端分页时使用这些信息。您可以尝试不同的请求,以查看它在其他场景中的工作原理。
We could also use this data to generate links to the previous and next pagination page on the backend, but that is part of the HATEOAS and is out of the scope of this chapter.
我们也可以使用这些数据在后端生成指向上一个和下一个分页页面的链接,但这是 HATEOAS 的一部分,超出了本章的范围。
16.4.1 Additional Advice
16.4.1 其他建议
This solution works great with a small amount of data, but with bigger tables with millions of rows, we can improve it by modifying the GetEmployeesAsync repository method:
此解决方案适用于少量数据,但对于具有数百万行的较大表,我们可以通过修改 GetEmployeesAsync 存储库方法来改进它:
public async Task<PagedList<Employee>> GetEmployeesAsync(Guid companyId, EmployeeParameters employeeParameters, bool trackChanges)
{
var employees = await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges)
.OrderBy(e => e.Name)
.Skip((employeeParameters.PageNumber - 1) * employeeParameters.PageSize)
.Take(employeeParameters.PageSize)
.ToListAsync();
var count = await FindByCondition(e => e.CompanyId.Equals(companyId), trackChanges).CountAsync();
return new PagedList<Employee>(employees, count, employeeParameters.PageNumber, employeeParameters.PageSize);
}Even though we have an additional call to the database with the CountAsync method, this solution was tested upon millions of rows and was much faster than the previous one. Because our table has few rows, we will continue using the previous solution, but feel free to switch to this one if you want.
尽管我们使用 CountAsync 方法对数据库进行了额外的调用,但此解决方案已在数百万行上进行了测试,并且比以前的解决方案快得多。由于我们的表的行数很少,因此我们将继续使用以前的解决方案,但如果需要,请随时切换到此解决方案。
Also, to enable the client application to read the new X-Pagination header that we’ve added in our action, we have to modify the CORS configuration:
此外,要使客户端应用程序能够读取我们在作中添加的新 X-Pagination 标头,我们必须修改 CORS 配置:
public static class ServiceExtensions
{
public static void ConfigureCors(this IServiceCollection services) =>
services.AddCors(options =>
{
options.AddPolicy("CorsPolicy", builder =>
builder.AllowAnyOrigin()
.AllowAnyMethod()
.AllowAnyHeader()
.WithExposedHeaders("X-Pagination"));
});
// ...
}